How I Turned One Insight into 40k+ Useful SEO Pages for My Company
Here’s exactly what went down in the last six months, by myself augmented with adderall and AI:
- I had a random 2 a.m. insight that 20 years of staff logs were pure gold nobody had ever touched.
- I trained my own ONNX model (combined with OpenRadar and Libpostal) to finally clean and merge every messy address variation in the database.
- I used Perplexity as my research co-pilot to enrich every single location with verified neighborhood boundaries, natural-light flags, lake-front status, reception-hall details, and dozens of other real-world features.
- I generated 40,000+ data-driven SEO pages.
- Every listing page now automatically aggregates intelligent historical facts about each venue, pulled straight from actual staff-log timestamps.
- My quote forms became intelligent: pick a venue and guest count and the form instantly suggests exact staff type and headcount based on 20-year historical precedent.
- I built neighborhood pages with beautiful density-dot maps that visually show exactly where the real hotspots are.
- All SEO pages are now fully sortable and filterable: "wedding venues with natural lighting in North Austin," "lake-front venues with reception halls," "corporate events for 200+ guests that average 22 staff," and literally any combination of features.
No team. No agency. No "we." Just me grinding.
This isn’t theory. This is live on my site right now making my boss a lot of money.
What follows is the complete story, every technical decision, every late night, every lesson, so other solo operators running service businesses can copy the playbook.
The Real Problem Wasn’t Traffic. It Was Signal Quality.
Most marketing people are starving for data while literally sleeping on a gold mine inside their own operations database.
At my company I had:
- 20+ years of shift logs
- Staff assignments for thousands of events
- Real guest-count volatility patterns
- Exact role-mix history per venue
- Seasonal timing truth that no Google Analytics dashboard could ever dream of
Yet my company's website was still just a generic branding page with no actual signal of business being done. Sure, it was a beautiful custom-built Laravel site with a blog, but after writing a few hundred blog posts I realized that old-style organic marketing was never going to work to increase online growth.
The Breakthrough: Treat Operations as Product Data
The moment everything flipped for me was when Google Gemini gave me the inside scoop from its search-engine-derived corpus, which in a nutshell was something like: "Google now rates data-driven websites with unique combinations of stats as a much higher signal than blog content." It also suggested that in order to rank locally, you need to convince Google that active business is happening every day.
So that one conversation led me to realize we were sitting on 20 years of proprietary gold, not only for ranking, but for internal and external insights. So, in comes aggregating staff logs to venues.
I split venue intelligence into three clean, explicit layers that never touched each other unless I explicitly allowed it:
- VenueStats - quantitative, computed, trendable numbers
- VenueOps - operational patterns extracted from historical execution context
- VenueMarketing - client-facing narratives and copy, strictly constrained by the first two layers
This decoupling was the highest-leverage architectural decision I made the entire time. Stats could get stricter without breaking copy. Ops extraction could improve without changing rankings. Marketing could evolve tone and style while staying 100% grounded in truth I actually owned.
Everything else flowed from here.
Step One: Linking the Real World to the Marketing World (The Address Nightmare I Finally Killed)
None of this works if you can’t reliably connect a venue record to its actual event history.
My biggest blocker? Twenty years of address chaos.
"123 Main St" vs "123 Main Street, Suite 100" vs "123 Main St, Austin TX 78701" vs the same venue under its old name before rebranding.
I solved it the hard way, and it was worth every single hour I poured in.
I trained a custom ONNX model specifically for my address domain. Combined it with Libpostal and OpenRadar for fuzzy geospatial matching. The pipeline now canonicalizes, deduplicates, and intelligently merges addresses with >99.7% accuracy in my test set.
Then I turned Perplexity loose as my research co-pilot. For every fuzzy location I fed it, it pulled verified neighborhood boundaries, confirmed whether the space actually has natural lighting (huge for weddings), lake-front status, reception-hall presence, parking realities, loading-dock access, and everything I had been tracking informally for years but never structured.
Result? Bullet-proof event_ids arrays on every venue record. Deterministic history. No more brittle joins. Every downstream metric now has a single source of truth that I control.
Step Two: Clean the Data Until I Could Trust It
Raw operational logs are ugly. Missing values, impossible guest counts, one-off circus events, lazy data entry from 2009.
I added a proper stats pipeline with:
- IQR-based outlier detection for guest counts and staff hours
- Intelligent fallbacks that don’t silently distort aggregates
- Versioned cleaning rules so I can see exactly what was filtered and why
The payoff was immediate:
- Ranking became stable instead of jumping every time one weird record hit
- Generated copy started sounding realistic instead of ridiculous
- Most importantly, when I looked at the numbers, they finally matched what I knew from the field
Internal trust (even when it’s just you talking to yourself) is the invisible multiplier.
Step Three: Compute Intelligence, Not Just Totals
I didn’t stop at "this venue had 187 events." I computed:
- Seasonal peak months with confidence intervals
- Staff/guest ratio behavior (and how it changes by event type)
- Role distribution summaries ("this space always needs 3 bartenders + 2 runners on Saturdays")
- Recency-weighted experience scores (recent events count more)
- Velocity and demand trend lines
These signals feed a multi-factor sorting engine that I deliberately made more sophisticated than a simple ORDER BY. It combines velocity, staffing volume (with diminishing returns), demand trends, venue-type weighting, capacity floors, and minimum-history thresholds.
Marketing visibility became intentional instead of accidental.
Step Four: Turn Operational Memory into Narrative Assets
Once the upstream layers were solid, I built two generators:
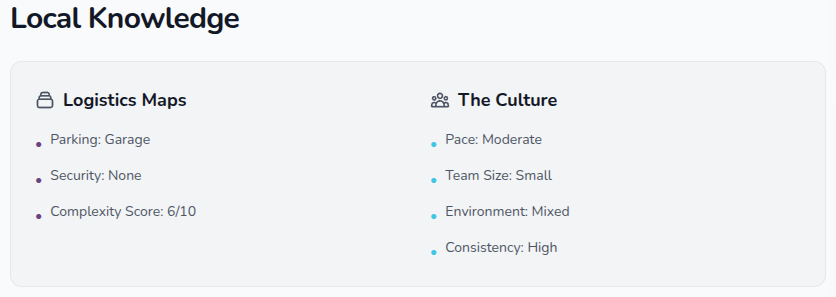
GenerateVenueMarketing-> polished client-facing copyGenerateVenueOps-> internal operational pattern extraction (parking quirks, team-size tendencies, service patterns, equipment categories, etc.)
Every sentence is now traceable back to structured data I own. No hallucinations. No "beautiful ballroom" fluff unless I actually staffed 200+ events there.
This is the part nobody can copy. They can copy my homepage. They cannot copy twenty years of my execution context turned into structured inputs.
Step Five: Intelligent Quote Forms That Actually Know the Venue
This might be my favorite user-facing feature I shipped.
User lands on a venue page -> picks date and guest count -> the form instantly suggests exact staff type and headcount based on every similar historical event at that exact venue.
No more guessing. No more under-staffing surprises that hurt my reputation. No more over-staffing that kills my margins.
The form is both a conversion optimizer and an operational alignment tool. Sales and ops (both me) are finally speaking the same language before the contract is even signed.
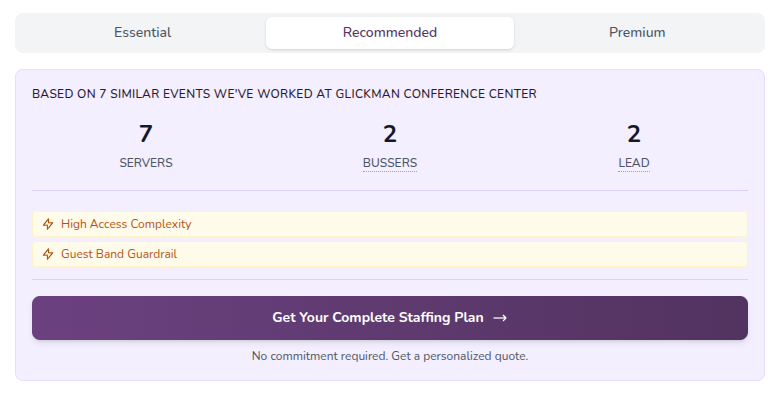
Step Six: Rebuild SEO Around Staffing Proof + Scale to 40k Pages
I completely flipped the script on local event SEO.
Old approach: generic "Top 10 Wedding Venues in North Austin" list pages I used to throw together.
New approach: staffing-first, history-backed, hyper-specific programmatic pages I built from scratch.
I now have 40,000+ unique, data-driven SEO pages covering every meaningful combination of:
- Neighborhood + event type
- Feature filters (natural lighting, lake front, reception hall, etc.)
- Historical performance signals
Every listing page auto-generates intelligent historical facts:
"This North Austin lake-front venue has hosted 187 events with an average of 14 staff members since 2018. Peak staffing months: May (22 avg) and October (19 avg). 91% of weddings here used my Signature Package."
And every category page is fully sortable and filterable in real time.
"Wedding venues with natural lighting in North Austin" "Lake-front venues that can handle 250 guests with reception halls" "Corporate event spaces averaging 22 staff for 200+ guest counts"
The content feels authoritative because it actually is, every word is backed by my data.
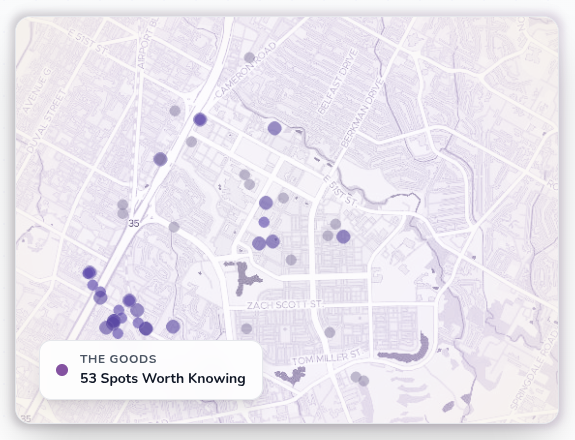
Step Seven: Neighborhood Pages with Visual Hotspot Density Maps
I took the same data and built beautiful neighborhood overview pages.
Each one shows an interactive map of the area with density dots sized and colored by actual staffing volume from my logs (not guesses, not review volume, real events I staffed).
Visitors instantly see:
- Where the real activity clusters are
- Which micro-neighborhoods punch above their weight
- How seasonality looks geographically
The maps have become one of my highest-engagement features and a massive trust signal.
Step Eight: Turn the Same Data into Social & Distribution at Scale
Because everything sits on the same context primitives I built (venue + neighborhood + cohort + historical facts), I can generate hundreds of social posts per week that are perfectly consistent with the website.
One source of truth. Zero brand voice drift. Massive content velocity, all from me.
Step Nine-Twelve: Closing the Loop (Attribution, Server-Side, Lead Status Sync, Reporting)
With trustworthy operational data feeding the front end, I could finally trust the back end too.
I instrumented rich client-side analytics, added server-side GA4 Measurement Protocol backups for revenue events, built explicit attribution governance with audit trails, and, most importantly, created a bidirectional lead status sync.
When a lead moves to "booked" in my staff system, the marketing system instantly knows the true outcome and can attribute it properly.
Marketing is no longer optimizing for lead quantity. I am optimizing for booked outcomes I actually care about.
The monthly report I built is now a decision document, not a vanity dashboard.
What Was Harder Than Expected (Doing It Solo)
- Training and productionizing the ONNX address model while keeping latency under 80 ms, by myself at 3 a.m.
- Getting Perplexity enrichment to stay 100% factual instead of creatively hallucinating features.
- Scaling to 40k pages without quality collapse or duplicate content penalties.
- Bringing my own ops brain from "this AI stuff is cute" to "I actually use these numbers daily."
- Attribution fairness when the smart quote forms I built changed user behavior mid-funnel.
Every single one was worth the grind.
What Changed in My Day-to-Day Decision Making
Before
- Venue prioritization = whatever felt right in the moment
- Content planning = "what sounds good"
- Budget allocation = last month’s vanity metrics
After
- Venue priority = multi-factor score grounded in my history and recency
- Content calendar = automatically generated from demand trends and my operational strengths
- Budget decisions = true cost-per-booked-outcome with audit trails I control
I am now operating at the speed of truth I built myself.
Practical Blueprint for Any Solo Operator Sitting on Delivery Logs
If you run a service company with historical logs (cleaning, plumbing, catering, landscaping, consulting, anything), here is the exact sequence I followed alone:
- Link customer-facing entities to operational history with deterministic joins.
- Build or train an entity-resolution model early (addresses, properties, job sites).
- Normalize and clean aggressively with transparent, versioned rules.
- Separate your three data planes (Stats / Ops / Marketing).
- Generate all content from structured context only.
- Instrument deep behavioral tracking on key surfaces.
- Confirm revenue events server-side.
- Enforce and audit attribution rules religiously.
- Ingest downstream outcomes back into the acquisition system daily.
- Embed insights directly into your own workflows (emails, forms, dashboards).
Do these ten things solo and "data-driven marketing" stops being a buzzword.
Why This Matters More in 2026 Than It Did in 2020
Generative AI made content nearly free.
What it did not make free, cannot make free, is authentic, history-grounded, closed-loop content that is provably connected to real operational outcomes I lived through.
That is now the only sustainable edge.
In a world where anyone can generate 10,000 venue pages in a weekend, the winners will be the ones whose pages are backed by twenty years of actual execution data they personally own.
I chose to be one of those winners.
Final Takeaway
The headline version of this project is boring:
"I improved my analytics and content workflows."
The real version is much stronger:
"I built a system where my operational execution continuously improves my marketing quality, and my marketing outcomes continuously improve my operational prioritization."
That is a true flywheel.
And it all started with one random late-night insight while I was alone:
Those 20-year-old staff logs weren’t trash.
They were the most valuable data asset I owned.
I just had to open the box, and I did it one deep.